
Nesse post vamos aprender com usar um modelo de Deep learning yolov3-tiny treinado para detectar se uma pessoa está usando máscara.
Geralmente quando discutimos sobre modelo de Deep learning , a acurácia é a principal métrica para comparar modelos. Para detecção de objeto em imagens até faz sentido. Mais, quando precisamos analisar vídeo em tempo real, o custo computacional ganha relevância. A maioria dos modelos de Deep learning precisão de GPU poderosas para processar vídeo em tempo real.
A arquitetura YOLO, é uma das propostas interessante para processamento em vídeo. E ainda conta com um modelo otimizado (-tiny) para rodar em CPU. O YOLO é uma das melhores arquiteturas de rede para consiliar velocidade e acurácia.
Motivação
Durante o período de quarentena devido a pandemia do covid-19, os principais autores de blog americanos apresentaram modelos de deep learning para detecção de máscaras. Eles utilizaram um modelo de detecção de face e projetaram um classificador para verificar se a pessoas estava usando máscara, confesso que é uma abordagem inteligente. Mais pensei, porque não treinar um modelo para isso, e além um modelo que não carrega dependência de bibliotecas pesadas como TensorFlow ou PyTorch?
Se você já precisou colocar um modelo em produção com dependências como TensorFlow, sabe porque isso não é bom. Primeiro, a maioria das ferramentas de empacotamento geralmente falha ao empacotar o TensorFlow (principalmente para windows), segundo, isso vai adicionar mais de 1 Gbs ao pacote final. E por último, é uma boa prática de programação não empacotar arquivo desnecessário em nossa aplicação.
Como YOLO funciona
Geralmente os algoritmos de detecção de objeto como: R-CNN, Fast R-CNN usam uma janela deslizante que percorre toda imagem. O YOLO é bem diferente, a imagem inteira é processada diretamente, é bem parecido com o SSD, porém o YOLO (YOLO-tiny) é mais rápido e atinge a mesma acurácia.
Para uma entrada de 416X416 o YOLO divide a imagem em células de 32×32, cada célula é responsável por prever um conjunto de caixas delimitadoras. A rede neural produz a previsão de cada uma dessas caixas conter um objeto e qual classe ele pertence.
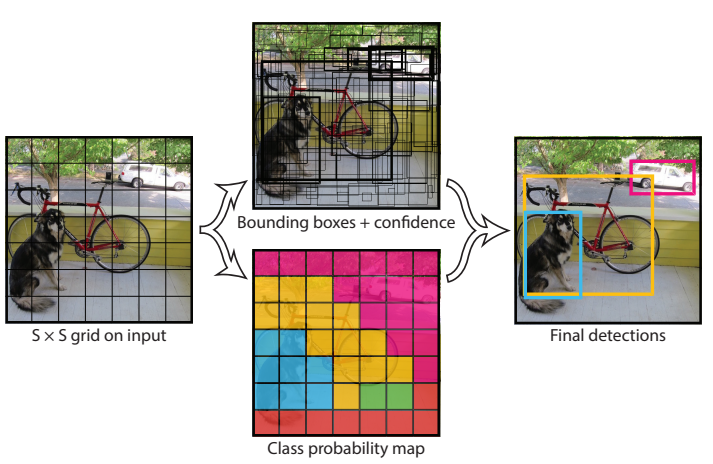
As caixas com níveis baixo de confiança são eliminadas restando apenas as caixas com os objetos detectados.
Do que você vai precisar?
Você pode clonar meu repositório git com os arquivos dessa lista, incluindo o código fonte eltonfernando projeto detect_mask.
- Python3.
- opencv-python ou opencv-contrib-python.
mask_yolov3-tiny.weights: Pesos treinados.classes.names:Arquivo com nome das classes.mask_yolov3-tiny.cfg: Arquivo com arquitetura da rede.
Os pesos foram treinado usando o dataset roboflow.
Usando YOLO
Estrutura do projeto .
$ tree ├── cfg │ └── mask_yolov3-tiny.cfg ├── data │ └── classes.names ├── weights │ └── mask_yolov3-tiny.weigts └── yolov3_video_mask.py
Temos três pastas cfg, data, weights onde colocamos os arquivos de configuração.
Como já mencionamos, para usar YOLO basta importar o OpenCV.
""" autor: Elton Fernandes dos Santos File: yolov3_video_mask.py """ import numpy as np import cv2 cap = cv2.VideoCapture(0) writer = None h, w = None, None
Por padrão usamos a webcam, mais isso pode ser alterado mudando o parâmetro 0 passado para Videocapture. writer é uma variável auxiliar que vamos usar para salvar o vídeo processado. h e w, são as dimensões do frame de entrada.
CLASSES = open('./data/classes.names').read().strip().split("\n")
weightsPath = './weights/mask_yolov3-tiny.weights'
configPath = './cfg/mask_yolov3-tiny.cfg'
Aqui, lemos o arquivo com os nomes das classes e salvamos na lista CLASSES. Também criamos variáveis com o caminho dos outros arquivos.
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
layers_names_all = net.getLayerNames()
layers_names_output = \
[layers_names_all[i[0] - 1] for i in net.getUnconnectedOutLayers()]
A função cv2.dnn.readNetFromDarknet carrega nosso modelo, criando um objeto net. Nas linhas seguintes pegamos as saídas das camadas YOLO. layers_names_output é uma lista contendo os nomes das camadas de saída, [yolo_16,yolo_23].
probability_minimum = 0.4 threshold = 0.3 colours = np.array([[255,0,0],[0,0,255]])
Detecções com nível de confiança menor que 0,4 e retângulos com mais de 30% de sobreposição serão ignorados. Colours são as cores que escolhemos para os retângulos.
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if w is None or h is None:
h, w = frame.shape[:2]
Iniciamos o fluxo de processamento. cap.read lê os frames do vídeo.
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),
swapRB=True, crop=False)
Usamos a função blobFromImage para pre-processar a imagem de entrada.
- 1/255.0 Esse fator será multiplicado pelos valores dos pixels. Nesse caso, normalizamos a entrada para valores de 0 a 1.
- (416,416) Largura e altura da imagem depois do pre-processamento. Seu vídeo pode ter qualquer resolução, porém se for muito diferente disso a imagem ficará distorcida dificultando a detecção.
- swapRB: Indica de vamos trocar os canais vermelho e azul de posição (lembrando que o OpenCV trabalha com imagem BGR e por isso precisamos mudar para RGB como usado no treinamento)
- crop: Quando a altura é diferente da largura um corte pode ser realizado para deixar a imagem quadrada. crop é uma bandeira que habilita essa operação quando True.
net.setInput(blob)
start = time.time()
output_blobs = net.forward(layers_names_output)
end = time.time()
bounding_boxes = []
confidences = []
class_numbers = []
Primeiro passamos nosso objeto blob como entrada da rede. forward calcula o resultado. Em seguida criamos 3 lista que vamos usar para manipular e mostrar os resultados das predições.
for result in output_blobs:
for detected_objects in result:
scores = detected_objects[5:]
class_current = np.argmax(scores)
confidence_current = scores[class_current]
if confidence_current > probability_minimum:
box_current = detected_objects[0:4] * np.array([w, h, w, h])
x_center, y_center, box_width, box_height = box_current
print(box_width)
x_min = int(x_center - (box_width / 2))
y_min = int(y_center - (box_height / 2))
bounding_boxes.append([x_min, y_min,
int(box_width), int(box_height)])
confidences.append(float(confidence_current))
class_numbers.append(class_current)
results = cv2.dnn.NMSBoxes(bounding_boxes, confidences,
probability_minimum, threshold)
if len(results) > 0:
for i in results.flatten():
x_min, y_min = bounding_boxes[i][0], bounding_boxes[i][1]
box_width, box_height = bounding_boxes[i][2], bounding_boxes[i][3]
colour_box_current = colours[class_numbers[i]].tolist()
cv2.rectangle(frame, (x_min, y_min),
(x_min + box_width+10, y_min + box_height+10),
colour_box_current, 2)
text_box_current = '{}: {:.4f}'.format(CLASSES[int(class_numbers[i])],
confidences[i])
cv2.putText(frame, text_box_current+" FPS "+str(round(1/(end-start))), (x_min, y_min-2),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, colour_box_current, 2)
Aqui coloquei o laço que percorre todas as predições. Calma, vamos continuar discutindo linha à linha, apenas coloquei assim para facilitar a vizualização de quais linhas estão dentro do laço for. O detected_objects é uma estrutura de lista individual para cada objeto predito. Nele temos as coordenadas de localização e probabilidade de pertencer a uma das classes.
scores = detected_objects[5:]
class_current = np.argmax(scores)
confidence_current = scores[class_current]
scores é uma lista de probabilidade para cada classe. Nesse caso temos duas, então ele é algo tipo [0.1 0.5] ou seja, esse face tem 10% de probabilidade de estar com máscara e 50% de ser o rosto sem máscara. Então, pegamos o índice de maior probabilidade com np.argmax e atribuímos o valor correspondente a confidence_current (0.5).
if confidence_current > probability_minimum:
box_current = detected_objects[0:4] * np.array([w, h, w, h])
x_center, y_center, box_width, box_height = box_current
x_min = int(x_center - (box_width / 2))
y_min = int(y_center - (box_height / 2))
Se a predição atende as condições mínimas que definimos no início (maior que 40%). Vamos guardar esse retângulo.
Nós multiplicamos por np.array([w, h, w, h]) porque a saída do YOLO é normalizada de 0 a 1.
O YOLO também retorna o centro e não as extremidade do retângulo, por isso precisamos calcular.
bounding_boxes.append([x_min, y_min,
int(box_width), int(box_height)])
confidences.append(float(confidence_current))
class_numbers.append(class_current)
results = cv2.dnn.NMSBoxes(bounding_boxes, confidences,
probability_minimum, threshold)
Nessas linhas nós adicionamos os resultados em uma lista. A função NMBoxes limita a sobreposição máxima dos retângulos, isso é necessário porque o YOLO pode prever mais de um retângulo para um mesmo objeto.
if len(results) > 0:
for i in results.flatten():
x_min, y_min = bounding_boxes[i][0], bounding_boxes[i][1]
box_width, box_height = bounding_boxes[i][2], bounding_boxes[i][3]
Em seguida percorremos os resultados, pegando as coordenadas de cada retângulo.
colour_box_current = colours[class_numbers[i]].tolist()
cv2.rectangle(frame, (x_min, y_min),
(x_min + box_width+10, y_min + box_height+10),
colour_box_current, 2)
text_box_current = '{}: {:.4f}'.format(CLASSES[int(class_numbers[i])],
confidences[i])
cv2.putText(frame, text_box_current+" FPS "+str(round(1/(end-start))), (x_min, y_min-2),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, colour_box_current, 2)
colour_box_current recebe a cor dependendo da classe detectada, se foram com máscara, azul sem máscara, vemelho. A função cv2.rectangle desenha o retângulo na imagem e cv2.putText escreve o nome da classe, confinaça da predição e a taxa de FPS.
cv2.imshow("frame",frame)
k = cv2.waitKey(1)
if k == ord("q"):
break
if writer is None:
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
writer = cv2.VideoWriter('saida.mp4', fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
writer.write(frame)
cap.release()
writer.release()
Por fim mostramos os resultados, criamos a estrutura para salvar o vídeo na primeira execução do laço.

Se você quer ver mais aplicações como essa, mais vídeo do YOLO em execução de uma olhada no meu instagram .
Baixe meu ebook grátis para saber mais sobre como iniciar carreira na área de visão computacional.
Limitação do YOLO
Quando divide a imagem para fazer as predições das caixas (exemplo citado 32X32) somente um objeto será detectado nessa região. De forma geral o YOLO não lida bem com objetos pequeno ou muito agrupados.
O SSDs também divide a imagem como o YOLO. Portando deve sofrer com as mesmas limitações.
O Faster R-CNN consegue detectar melhor objetos pequenos. Porém é mais lento.
Conclusão
O YOLO é uma das técnicas mais modernas em detecção de objetos. No artigo original (https://arxiv.org/abs/1506.02640) os autores usaram o banco de dado COCO para treinar e prever 80 classes, isso é fantástico. Porém, boa parte das aplicações, assim como essa não vamos precisar de 80 classes então podemos pensar, será que é possivel otimizar a arquitetura para problemas mais simples? A resposta é sim, claro isso vai da (trabalho) e exigir conhecimento avançado em Deep learning. Entretando podemos obter soluções ótimas para aplicações reais.
Caso tenha alguma dúvida ou ideia de como usar YOLO, me deixe saber aqui nos comentários. Se encontrou algum erro nesse artigo, por favor nos avise, parabéns por ter chegado até aqui e muito obrigado.
2 Replies to “Detecção de máscara em tempo real usando yolov3-tiny”
I am sure this article has touched all the internet visitors, its really really pleasant post on building up new web site. Gena Meir Dart
Very good post. I certainly appreciate this website. Jerry Burk Mara